UAVSAR Data Access and Conversion¶
Learning Objectives
overview of UAVSAR data (both InSAR and PolSAR products)
demonstrate how to access and transform data to Geotiffs
There are multiple ways to access UAVSAR data. Also the SQL database.
InSAR Data Types
ANN file (.ann): a text annotation file with metadata
AMP files (.amp1 and .amp2): calibrated multi-looked amplitude products
INT files (.int): interferogram product, complex number format (we won’t be using these here)
COR files (.cor): interferometric correlation product, a measure of the noise level of the phase
GRD files (.grd): interferometric products projected to the ground in simple geographic coordinates (latitude, longitude)
HGT file (.hgt): the DEM that was used in the InSAR processing
KML and KMZ files (.kml or .kmz): format for viewing files in Google Earth (can’t be used for analysis)
# import libraries
import re
import zipfile
import getpass
from osgeo import gdal
import os # for chdir, getcwd, path.basename, path.exists
import pandas as pd # for DatetimeIndex
import codecs # for text parsing code
import netrc
import rasterio as rio
import glob
Data Download¶
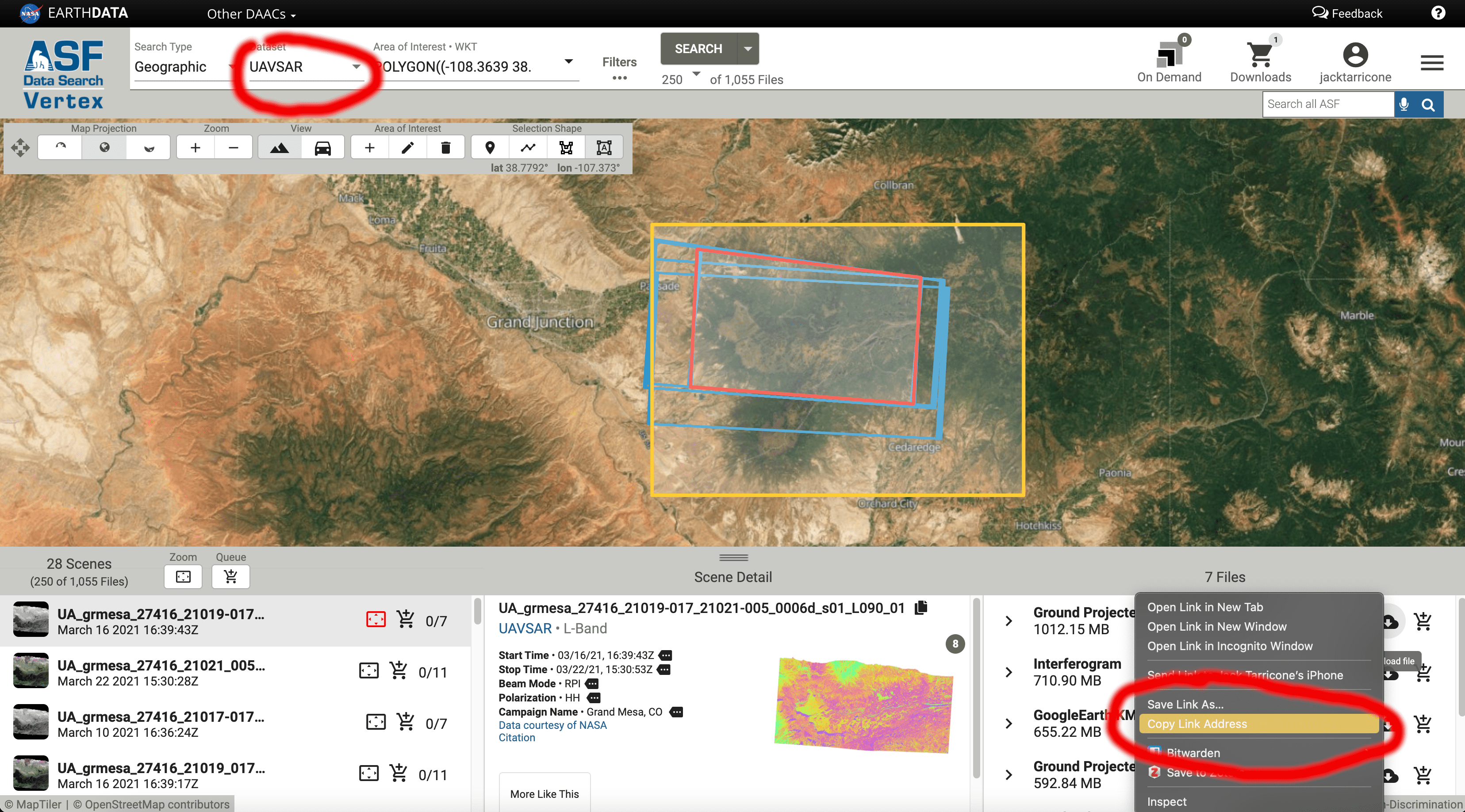
We will use our NASA EarthData credentials and ASF Vertex to download an InSAR pair data into our notebook directly. For this tutorial, we will be working with UAVSAR data from February of 2020. If you want to use different data in the future, change the links in the files variable. The screengrab below shows how I generated these download links from the ASF site.
# Get NASA EARTHDATA Credentials from ~/.netrc or manual input
try:
os.chmod('/home/jovyan/.netrc', 0o600) #only necessary on jupyterhub
(ASF_USER, account, ASF_PASS) = netrc.netrc().authenticators("urs.earthdata.nasa.gov")
except:
ASF_USER = input("Enter Username: ")
ASF_PASS = getpass.getpass("Enter Password: ")
# directory in which the notebook resides
if 'tutorial_home_dir' not in globals():
tutorial_home_dir = os.getcwd()
print("Notebook directory: ", tutorial_home_dir)
if not os.path.exists('/tmp/'):
os.chdir('/tmp')
# directory for data downloads
data_dir = os.path.join('/tmp')
os.makedirs(data_dir, exist_ok=True)
print(data_dir)
%%time
files = ['https://datapool.asf.alaska.edu/INTERFEROMETRY_GRD/UA/grmesa_27416_20003-028_20005-007_0011d_s01_L090_01_int_grd.zip',
'https://datapool.asf.alaska.edu/AMPLITUDE_GRD/UA/grmesa_27416_20003-028_20005-007_0011d_s01_L090_01_amp_grd.zip']
for file in files:
print(f'downloading {file}...')
filename = os.path.basename(file)
if not os.path.exists(os.path.join(data_dir,filename)):
cmd = "wget -q {0} --user={1} --password={2} -P {3} -nc".format(file, ASF_USER, ASF_PASS, data_dir)
os.system(cmd)
else:
print(filename + " already exists. Skipping download ..")
print("done")
# check to see if downloaded
# the *.* syntax means print all files in the directory
print(glob.glob("/tmp/*.*"))
#use for deleting contents of temp directory if needed. DO NOT uncomment, this will cause the notebook to fail.
#files = glob.glob("/tmp/*.*")
#for f in files:
# os.remove(f)
Unzipping the files we just downloaded¶
## unzip files just downloaded
# define file path for both files
int_zip = '/tmp/grmesa_27416_20003-028_20005-007_0011d_s01_L090_01_int_grd.zip'
amp_zip = '/tmp/grmesa_27416_20003-028_20005-007_0011d_s01_L090_01_amp_grd.zip'
# unzip
# int
with zipfile.ZipFile(int_zip, "r") as zip_ref:
zip_ref.printdir()
print('Extracting all the files now...')
zip_ref.extractall('/tmp')
print("done")
# amp
with zipfile.ZipFile(amp_zip, "r") as zip_ref:
zip_ref.printdir()
print('Extracting all the files now...')
zip_ref.extractall('/tmp')
print("done")
Removing unwanted data¶
For simplicity, we’ll only work with HH polarization. The three other polarizations (VV, VH, HV) provide additional information about the surface properties and can be utilized in further analysis.
# clean up unwanted data from what we just downloaded
directory = '/tmp'
os.chdir(directory)
HV_files = glob.glob('*HV_01*') #define all HV
VV_files = glob.glob('*VV_01*') #define all VV
VH_files = glob.glob('*VH_01*') #define all VH
zips = glob.glob('*.zip') # define the zip files
# loops to remove them
for f in HV_files:
os.remove(f)
for f in VV_files:
os.remove(f)
for f in VH_files:
os.remove(f)
for f in zips:
os.remove(f)
# check to see what files are left in the directory
print(glob.glob("/tmp/*.*"))
Now we only have the HH polarization, the annotation file, and the 6 .grd files!
Converting Data to GeoTiffs¶
The downloadable UAVSAR data comes in a flat binary format (.grd), which is not readable by GDAL (Geospatial Data Abstraction Library). Therefore it needs to be transformed for use in standard spatial analysis software (ArcGIS, QGIS, Python, R, MATLAB, etc.). To do this, we will use the uavsar_tiff_convert function, which takes information (latitude, longitude, number of lines and samples, data type, pixel size) from the annotation file to create an ENVI header (.hdr). Once the ENVI header is created, the files can be read into Python and converted to GeoTiffs.
# First, let's print the annotation file to get a look at it's content
# these file contain a lot of information and can be very intimidating and hard to understand, but being able to read them is vital to working this UAVSAR data
#f = open('/tmp/grmesa_27416_20003-028_20005-007_0011d_s01_L090HH_01.ann', 'r')
#file_contents = f.read()
#print (file_contents)
!head -n 15 /tmp/grmesa_27416_20003-028_20005-007_0011d_s01_L090HH_01.ann
This function pulls out information from the annotation file, builds and ENVI header, and then converts the data to GeoTIFFS.
# folder is path to a folder with an .ann (or .txt) and .grd files (.amp1, .amp2, .cor, .unw, .int)
def uavsar_tiff_convert(folder):
"""
Builds a header file for the input UAVSAR .grd file,
allowing the data to be read as a raster dataset.
:param folder: the folder containing the UAVSAR .grd and .ann files
"""
os.chdir(folder)
int_file = glob.glob(os.path.join(folder, 'int.grd'))
# Empty lists to put information that will be recalled later.
Lines_list = []
Samples_list = []
Latitude_list = []
Longitude_list = []
Files_list = []
# Step 1: Look through folder and determine how many different flights there are
# by looking at the HDR files.
for files in os.listdir(folder):
if files [-4:] == ".grd":
newfile = open(files[0:-4] + ".hdr", 'w')
newfile.write("""ENVI
description = {DESCFIELD}
samples = NSAMP
lines = NLINE
bands = 1
header offset = 0
data type = DATTYPE
interleave = bsq
sensor type = UAVSAR L-Band
byte order = 0
map info = {Geographic Lat/Lon,
1.000,
1.000,
LON,
LAT,
0.0000555600000000,
0.0000555600000000,
WGS-84, units=Degrees}
wavelength units = Unknown
"""
)
newfile.close()
if files[0:18] not in Files_list:
Files_list.append(files[0:18])
#Variables used to recall indexed values.
var1 = 0
#Step 2: Look through the folder and locate the annotation file(s).
# These can be in either .txt or .ann file types.
for files in os.listdir(folder):
if Files_list[var1] and files[-4:] == ".txt" or files[-4:] == ".ann":
#Step 3: Once located, find the info we are interested in and append it to
# the appropriate list. We limit the variables to <=1 so that they only
# return two values (one for each polarization of
searchfile = codecs.open(files, encoding = 'windows-1252', errors='ignore')
for line in searchfile:
if "Ground Range Data Latitude Lines" in line:
Lines = line[65:70]
print(f"Number of Lines: {Lines}")
if Lines not in Lines_list:
Lines_list.append(Lines)
elif "Ground Range Data Longitude Samples" in line:
Samples = line[65:70]
print(f"Number of Samples: {Samples}")
if Samples not in Samples_list:
Samples_list.append(Samples)
elif "Ground Range Data Starting Latitude" in line:
Latitude = line[65:85]
print(f"Top left lat: {Latitude}")
if Latitude not in Latitude_list:
Latitude_list.append(Latitude)
elif "Ground Range Data Starting Longitude" in line:
Longitude = line[65:85]
print(f"Top left Lon: {Longitude}")
if Longitude not in Longitude_list:
Longitude_list.append(Longitude)
#Reset the variables to zero for each different flight date.
var1 = 0
searchfile.close()
# Step 3: Open .hdr file and replace data for all type 4 (real numbers) data
# this all the .grd files expect for .int
for files in os.listdir(folder):
if files[-4:] == ".hdr":
with open(files, "r") as sources:
lines = sources.readlines()
with open(files, "w") as sources:
for line in lines:
if "data type = DATTYPE" in line:
sources.write(re.sub(line[12:19], "4", line))
elif "DESCFIELD" in line:
sources.write(re.sub(line[15:24], folder, line))
elif "lines" in line:
sources.write(re.sub(line[8:13], Lines, line))
elif "samples" in line:
sources.write(re.sub(line[10:15], Samples, line))
elif "LAT" in line:
sources.write(re.sub(line[12:15], Latitude, line))
elif "LON" in line:
sources.write(re.sub(line[12:15], Longitude, line))
else:
sources.write(re.sub(line, line, line))
# Step 3: Open .hdr file and replace data for .int file date type 6 (complex)
for files in os.listdir(folder):
if files[-8:] == ".int.hdr":
with open(files, "r") as sources:
lines = sources.readlines()
with open(files, "w") as sources:
for line in lines:
if "data type = 4" in line:
sources.write(re.sub(line[12:13], "6", line))
elif "DESCFIELD" in line:
sources.write(re.sub(line[15:24], folder, line))
elif "lines" in line:
sources.write(re.sub(line[8:13], Lines, line))
elif "samples" in line:
sources.write(re.sub(line[10:15], Samples, line))
elif "LAT" in line:
sources.write(re.sub(line[12:15], Latitude, line))
elif "LON" in line:
sources.write(re.sub(line[12:15], Longitude, line))
else:
sources.write(re.sub(line, line, line))
# Step 4: Now we have an .hdr file, the data is geocoded and can be loaded into python with rasterio
# once loaded in we use gdal.Translate to convert and save as a .tiff
data_to_process = glob.glob(os.path.join(folder, '*.grd')) # list all .grd files
for data_path in data_to_process: # loop to open and translate .grd to .tiff, and save .tiffs using gdal
raster_dataset = gdal.Open(data_path, gdal.GA_ReadOnly)
raster = gdal.Translate(os.path.join(folder, os.path.basename(data_path) + '.tiff'), raster_dataset, format = 'Gtiff', outputType = gdal.GDT_Float32)
# Step 5: Save the .int raster, needs separate save because of the complex format
data_to_process = glob.glob(os.path.join(folder, '*.int.grd')) # list all .int.grd files (only 1)
for data_path in data_to_process:
raster_dataset = gdal.Open(data_path, gdal.GA_ReadOnly)
raster = gdal.Translate(os.path.join(folder, os.path.basename(data_path) + '.tiff'), raster_dataset, format = 'Gtiff', outputType = gdal.GDT_CFloat32)
print(".tiffs have been created")
return
data_folder = '/tmp' # define folder where the .grd and .ann files are
uavsar_tiff_convert(data_folder) # call the tiff convert function, and it will print the information it extracted from the .ann file
Now we’ll delete the unneeded .grd and .hdr files that our tiffs have been created. If you’re using this code on your local machine, this probably isn’t absolutely necessary. The JupyterHub cloud we’re working in has limited space, so deletion is needed.
os.chdir(data_folder)
grd = glob.glob('*.grd') #define .grd
hdr = glob.glob('*.hdr*') #define .hdr
# remove both
for f in grd:
os.remove(f)
for f in hdr:
os.remove(f)
# check what's in the directory, only .tiffs and our annotation file!
print(glob.glob("*.*"))
### inspect our newly created .tiffs, and create named objects for each data type. We'll use these new obects in the next step
# amplitude from the first acquisition
for amp1 in glob.glob("*amp1.grd.tiff"):
print(amp1)
# amplitude from the second acquisition
for amp2 in glob.glob("*amp2.grd.tiff"):
print(amp2)
# coherence
for cor in glob.glob("*cor.grd.tiff"):
print(cor)
# unwrapped phase
for unw in glob.glob("*unw.grd.tiff"):
print(unw)
# dem used in processing
for dem in glob.glob("*hgt.grd.tiff"):
print(dem)
Inspect the meta data the rasters using the rio (shorthand for rasterio) profile function.
unw_rast = rio.open(unw)
meta_data = unw_rast.profile
print(meta_data)