NASA Land Information System (LIS)¶

Contributors: Melissa Wrzesien1,4, Brendan McAndrew2,4, Jian Li3,5
1 Universities Space Research Association, 2 Science Systems and Applications, Inc., 3 InuTeq, LLC, 4 Hydrological Sciences Branch, NASA Goddard Space Flight Center, 5 Computational and Information Sciences and Technology Office (CISTO), NASA Goddard Space Flight
Learning Objectives
Learn about NASA’s Land Information System
Open, explore, and visualize LIS output
Compare LIS simulation output to raster- and point-based observation datasets
Duration: 45 min
What is LIS?¶
The Land Information System (LIS) is a software framework for high performance terrestrial hydrology modeling and data assimilation developed with the goal of integrating satellite and ground-based observational data products and advanced modeling techniques to produce optimal fields of land surface states and fluxes.
TL;DR LIS = land surface models + data assimilation
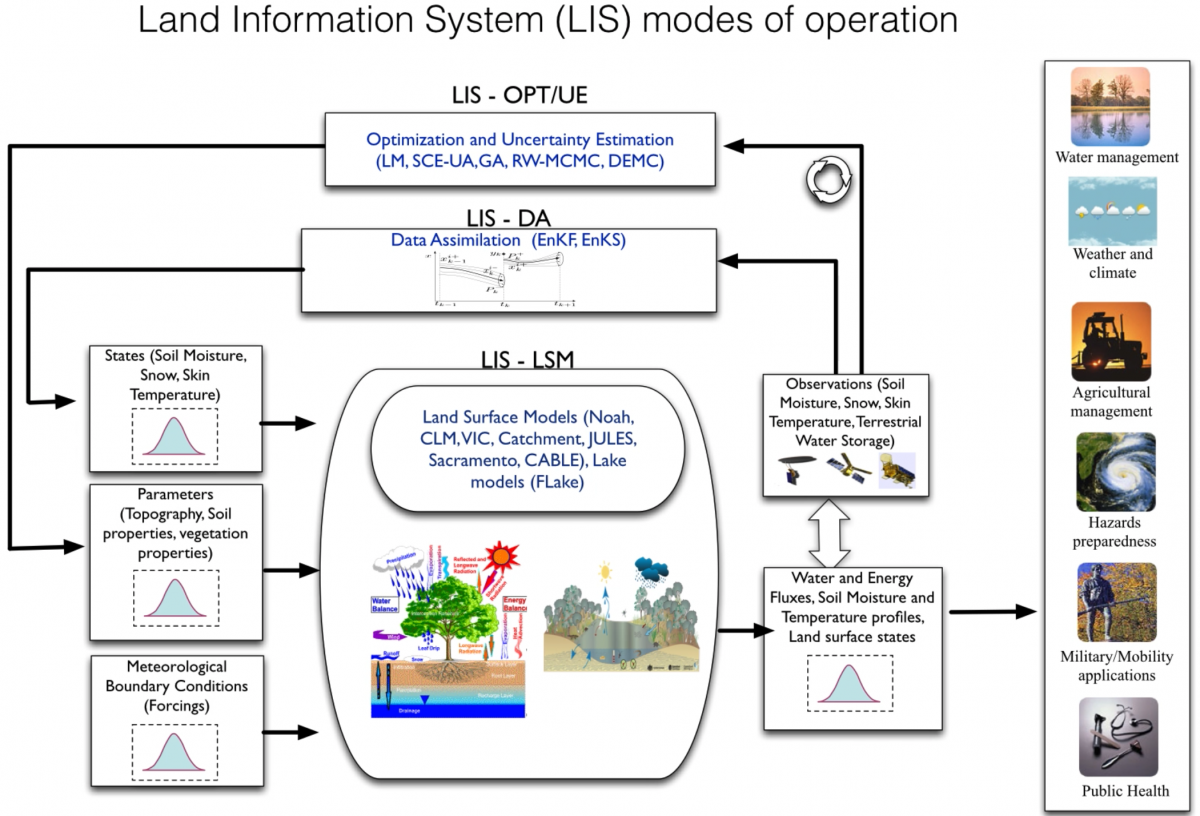
Fig. 10 Diagram of components of NASA LIS framework. (Image source: https://lis.gsfc.nasa.gov/software/lis/)¶
One key feature LIS provides is flexibility to meet user needs. LIS consists of a collection of plug-ins, or modules, that allow users to design simulations with their choice of land surface model, meteorological forcing, data assimilation, hydrological routing, land surface parameters, and more. The plug-in based design also provides extensibility, making it easier to add new functionality to the LIS framework.
Current efforts to expand support for snow modeling include implementation of snow modules, such as SnowModel and Crocus, into the LIS framework. These models, when run at the scale of ~100 meters, will enable simulation of wind redistribution, snow grain size, and other important processes for more accurate snow modeling.
Development of LIS is led by the Hydrological Sciences Laboratory at NASA’s Goddard Space Flight Center.
More information
Links
References
Kumar, S.V., C.D. Peters-Lidard, Y. Tian, P.R. Houser, J. Geiger, S. Olden, L. Lighty, J.L. Eastman, B. Doty, P. Dirmeyer, J. Adams, K. Mitchell, E. F. Wood, and J. Sheffield, 2006: Land Information System - An interoperable framework for high resolution land surface modeling. Environ. Modeling & Software, 21, 1402-1415, doi:10.1016/j.envsoft.2005.07.004
Peters-Lidard, C.D., P.R. Houser, Y. Tian, S.V. Kumar, J. Geiger, S. Olden, L. Lighty, B. Doty, P. Dirmeyer, J. Adams, K. Mitchell, E.F. Wood, and J. Sheffield, 2007: High-performance Earth system modeling with NASA/GSFC’s Land Information System. Innovations in Systems and Software Engineering, 3(3), 157-165, doi:10.1007/s11334-007-0028-x
Tutorial Datasets¶
LIS Output¶
LIS generates gridded output with support for several filetypes: Fortran binary, GRIB1, and NetCDF. In this tutorial we will be using outputs originally generated as NetCDF files that have been converted into a Zarr store. Why Zarr? We’ve been exploring cloud-based analysis pipelines and Zarr provides better performance when working with cloud-hosted data. More on this later…
The table below describes the configuration options of the simulation used to generate the output we’ll be working with:
Domain |
Simulation Period |
Spatial Resolution |
Land Surface Model |
Meteorological Forcing |
Data Assimilated |
Output Frequency |
|---|---|---|---|---|---|---|
Mississippi River Basin |
10/2016-09/2018 |
0.1° x 0.1° (~10km) |
NoahMP 4.0.1 |
MERRA2 |
SNODAS |
Daily |
Map of the simulation domain:
Comparison Datasets¶
We will compare the gridded LIS output to two types of data: raster and point data. For the raster comparison, we will use the SNODAS dataset. For the point comparison, we will use SNOTEL station data.
SNODAS¶
SNODAS (or the Snow Data Assimilation System) is a gridded dataset that combined ground observations with a model to estimate daily snow depth and SWE across the contiguous United States at approximately 1 km spatial resolution. SNODAS is produced by NOAA and is available for download at the NSIDC. This data is distributed as a flat binary and instructions are provided to convert to NetCDF or GeoTIFF. Similar to the LIS output, we have further converted this to Zarr store for this tutorial.
SNOTEL¶
The SNOTEL (or Snow Telemetry) network includes over 800 automatic stations across the western US, including Alaska. SNOTEL stations report SWE, snow depth, and other meteorological variables. SNOTEL is run by the USDA and is available for download at the NRCS website. This data is text-based.